本篇文章主要介绍了"服务器监控包括性能指标与web应用程序",主要涉及到服务器监控,应用程序方面的内容,对于系统运维感兴趣的同学可以参考一下:
服务器监控?? 在搭建服务器时,除了部署webapp之外,还需要服务的异常信息与服务器性能指标进行监控,一旦有异常则通知管理员。
?? 服务器使用Linux+...
服务器监控
?? 在搭建服务器时,除了部署webapp之外,还需要服务的异常信息与服务器性能指标进行监控,一旦有异常则通知管理员。
?? 服务器使用Linux+Nginx-1.9.15+Tomcat7+Java搭建的。
?? 编写脚本检测错误日志和服务器性能指标,一旦新生错误日志或者性能降低到设定的阈值时,则使用云监控将报警上传到云账号。
服务运行监控
?? 错误日志包含以下三个方面:
- nginx 错误信息监控(nginx.conf配置)
- ${NGINX_HOME}/logs/error.log
- tomcat 错误信息监控(server.xml配置)
- ${TOMCAT_HOME}/logs/catalina.out
- webapp错误信息监控(log4j)
机器性能指标
?? 一般都会使用linux系统的机器作为服务器,那么当在上面搭建服务时,需要对一些常用的性能指标进行监控,那么一般包含哪些指标呢?下面对其进行一些总结,欢迎补充…
指标
- CPU(Load) CPU使用率/负载
- Memory 内存
- Disk 磁盘空间
- Disk I/O 磁盘I/O
- Network I/O 网络I/O
- Connect Num 连接数
- File Handle Num 文件句柄数
…
CPU
说明
?? 机器的CPU占有率越高,说明机器处理越忙,运算型任务越多。一个任务可能不仅会有运算部分,还会有I/O(磁盘I/O与网络I/O)部分,当在处理I/O时,时间片未完其CPU也会释放,因此某个时间点的CPU占有率没有太大的意义,因此需要计算一段时间内的平均值,那么平均负载(Load Average)这个指标便能很好得对其进行表征。平均负载:它是根据一段时间内占有CPU的进程数目和等待CPU的进程数目计算出来的,其中等待CPU的进程不包括处于wait状态的进程,比如在等待I/O的进程,即指那些就绪状态的进程,运行只缺CPU这个资源。具体如何计算可以参见Linux内核代码,计算出一个数之后,然后除以CPU核数,结果:
- <=3 则系统性能较好。
- <=4 则系统性能可以,可以接收。
- >5 则系统性能负载过重,可能会发生严重的问题,那么就需要扩容了,要么增加核,要么分布式集群。
查看命令
vmstat
vmstat n m
n表示每隔n秒采集一次,m表示一共采集多少次,如果m没有,那么会一直采集下去. 在终端键入 vmstat 5

结果各字段解释如下(这里只解释与CPU相关的):
r:表示运行队列(就是说多少个进程真的分配到CPU),当这个值超过了CPU数目,就会出现CPU瓶颈了。这个也和top的负载有关系,一般负载超过了3就比较高,超过了5就高,超过了10就不正常了,服务器的状态很危险。top的负载类似每秒的运行队列。如果运行队列过大,表示你的CPU很繁忙,一般会造成CPU使用率很高。
b:表示阻塞的进程,如在等待I/O请求。
in:每秒CPU的中断次数,包括时间中断。
cs:每秒上下文切换次数,例如我们调用系统函数,就要进行上下文切换,线程的切换,也要进程上下文切换,这个值要越小越好,太大了,要考虑调低线程或者进程的数目,例如在apache和nginx这种web服务器中,我们一般做性能测试时会进行几千并发甚至几万并发的测试,选择web服务器的进程可以由进程或者线程的峰值一直下调,压测,直到cs到一个比较小的值,这个进程和线程数就是比较合适的值了。系统调用也是,每次调用系统函数,我们的代码就会进入内核空间,导致上下文切换,这个是很耗资源,也要尽量避免频繁调用系统函数。上下文切换次数过多表示你的CPU大部分浪费在上下文切换,导致CPU干正经事的时间少了,CPU没有充分利用,是不可取的。
us:用户CPU时间占比(%),例如在做高运算的任务时,如加密解密,那么会导致us很大,这样,r也会变大,造成系统瓶颈。
sy:系统CPU时间占比(%),如果太高,表示系统调用时间长,如IO频繁操作。
id :空闲 CPU时间占比(%),一般来说,id + us + sy = 100,一般认为id是空闲CPU使用率,us是用户CPU使用率,sy是系统CPU使用率。
wt:等待IO的CPU时间。uptime

17:53:46为当前时间
up 158 days, 6:23机器运行时间,时间越大说明你的机器越稳定
2 users用户连接数,而不是总用户数
oad average: 0.00, 0.00, 0.00 最近1分钟,5分钟,15分钟的系统平均负载。
将平均负载值除以核数,如果结果不大于3,那么系统性能较好,如果不大于4那么系统性能可以接受,如果大于5,那么系统性能较差。top
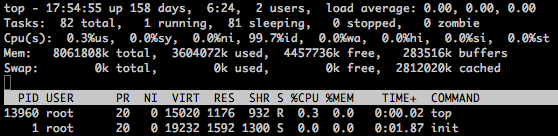
top命令用于显示进程信息,top详细见http://www.cnblogs.com/peida/archive/2012/12/24/2831353.html
这里主要关注Cpu(s)统计那一行:
us:用户空间占用CPU的百分比
sy:内核空间占用CPU的百分比
ni:改变过优先级的进程占用CPU的百分比
id: 空闲CPU百分比
wa: IO等待占用CPU的百分比
hi:硬中断(Hardware IRQ)占用CPU的百分比
si:软中断(Software Interrupts)占用CPU的百分比
从top的结果看CPU负载情况,主要看us和sy,其中us<=70,sy<=35,us+sy<=70说明状态良好,同时可以结合idle值来看,如果id<=70 则表示IO的压力较大。也可以和uptime一样,看第一行。引用[1]
- 分析
表示系统CPU正常,主要有以下规则:
- CPU利用率:us <= 70,sy <= 35,us + sy <= 70。引用[1]
- 上下文切换:与CPU利用率相关联,如果CPU利用率状态良好,大量的上下文切换也是可以接受的。引用[1]
- 可运行队列:每个处理器的可运行队列<=3个线程。
Memory
- 说明
?? 内存也是系统运行性能的一个很重要的指标,如果一个机器内存不足,那么将会导致进程运行异常而退出。如果进程发生内存泄漏,则会导致大量内存被浪费而无足够可用内存。内存监控一般包括total(机器总内存)、free(机器可用内存)、swap(交换区大小)、cache(缓存大小)等。 查看命令
