本篇文章主要介绍了" MySQL查询优化器工作原理解析",主要涉及到方面的内容,对于其他数据库感兴趣的同学可以参考一下:
查询优化器的任务是发现执行SQL查询的最佳方案。大多数查询优化器,包括MySQL的查询优化器,总是或多或少地在所有可能的查询评估方案中搜索最佳方案。对于联接查询...
select * from t8 where id1=1 and id2=0;
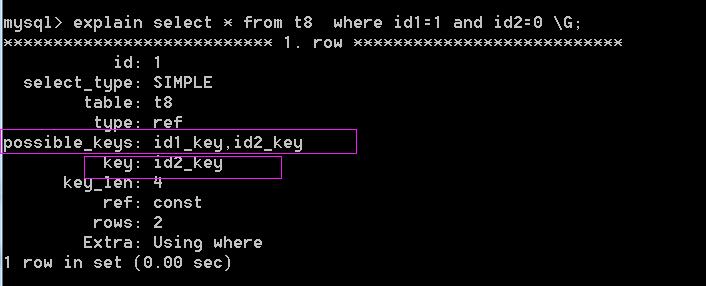
当然,MySQL不会傻到,从t8表中的一行开始,然后一行行的去比较,id1与id2。优化器会先分析数据表,得知有索引id1_key与id2_key,如果先判断id1_key的话,然后需要从4行数据中排除3行数据;如果先判断id2_key的话,然后需要从2行中排除1行。对人来说,这两种方式没有什么区别,但是对于程序而言,先判断id2_key需要较少的计算和磁盘输入输出。因此,查询优化器会规定程序,先去检验id2_key索引,然后在从中挑出id2为0的数据行。
通过下图,我们可以看出,可以选择的索引有id1_key与id2_key,但是实际用到的索引只有id2_key
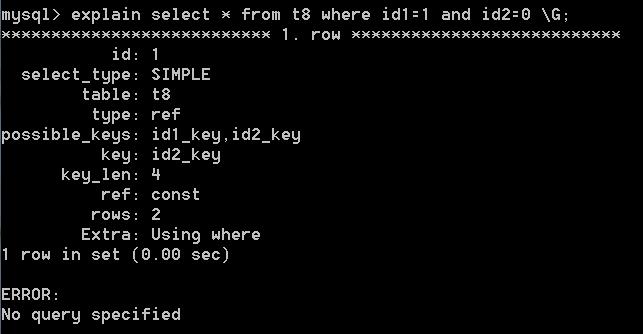
如果将SQL语句改为 select * from t8 where id1=1 and id2=0;执行情况也是一样的,不区分前后。如下图:
当然,如果将程序,修改为如下
select * from t8 where id1=5 and id2=0;
也可以分析得出,会使用id1_key索引

当然,如果在创建一个复合索引
ALTER TABLE t8 ADD KEY id1_id2_key(`id1`,`id2`)
此时,在此执行select * from t8 where id1=1 and id2=0; 当然会考虑使用id1_id2_key索引。

通过上面的例子,可以理解查询优化器在查询的时候,是选择哪一个索引作为最合适的索引。除此,也提示我们,要慎重选择创建索引。如,上面创建了三个索引(id1_key、id1_key、id1_id2_key),但是优化器优化程序时候,每次只能从中选择一个最合适的,如果创建过多,不仅仅是给数据的更新和插入带来了压力,同时也增加了优化器的压力。
一般情况下,MySQL优化器会自行决定按照哪种顺序扫描数据表才能最快地检索出数据
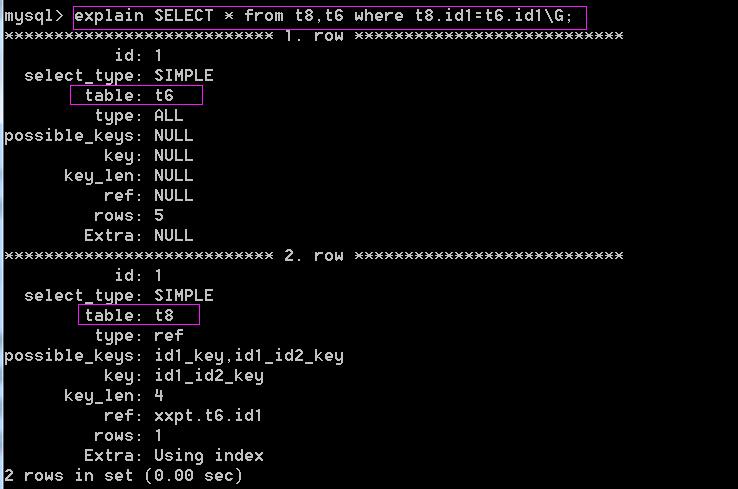

可以看出,无论from t8,t6还是from t6,t8,都是先检索t6中的表为什么优化器要选择先判断t6中的数据呢?一个主要的原因,因为t6中数据更少。

控制查询缓冲
在实际开发中,一些数据对实时性要求特别高,或者并不经常使用(可能几天就执行一次或两次),这样就需要把缓冲关了,不管这条SQL语句是否被执行过,服务器都不会在缓冲区中查找该数据,每次都会从磁盘中读取。因为如果实时性要求特别高,缓存中数据可能和磁盘中的就不同步,如果数据不经常使用,被缓存起来,就会占用内存。
在my.ini中的query_cache_type,使用来控制表缓存的。这个变量有三个取值:0,1,2,分别代表了off、on、demand。
0:表示query cache 是关闭。
1:表示查询总是先到查询缓存中查找,即使使用了sql_no_cache仍然查询缓存,因为sql_no_cache只是不缓存查询结果,而不是不使用查询结果。
2:表示只有在使用了SQL_CACHE后,才先从缓冲中查询数据,仍然将查询结果缓存起来。
我本地缓存是关闭的,如下图。

以上就介绍了 MySQL查询优化器工作原理解析,包括了方面的内容,希望对其他数据库有兴趣的朋友有所帮助。
本文网址链接:http://www.codes51.com/article/detail_4570318_2.html
